Understanding Mixtral-8x7b
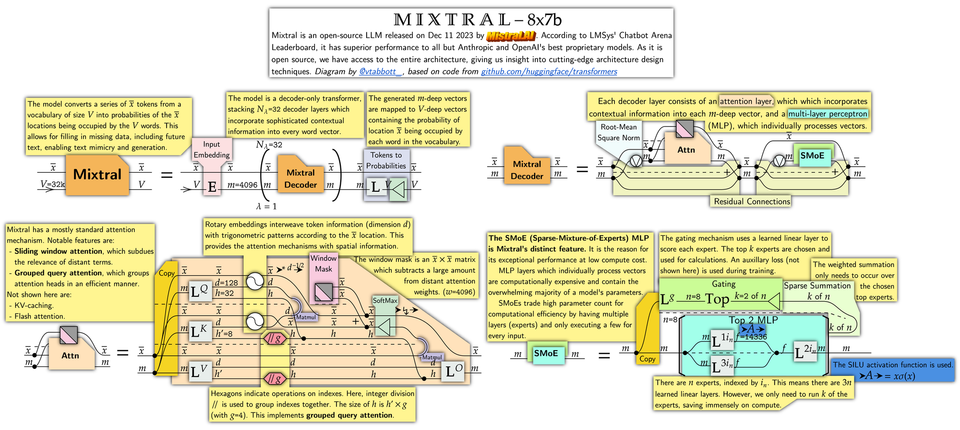
This blog post is adapted from an X thread I posted. Its garnered significant interest, so I decided to post it here as well!
Mixtral-8x7b by @MistralAI is an LLM that outperforms all but OpenAI and Anthropic's most powerful models. And, it is open-source. In this blog post, I will explain its architecture design using my Neural Circuit Diagrams. Let's dive in and see how cutting edge transformers work!
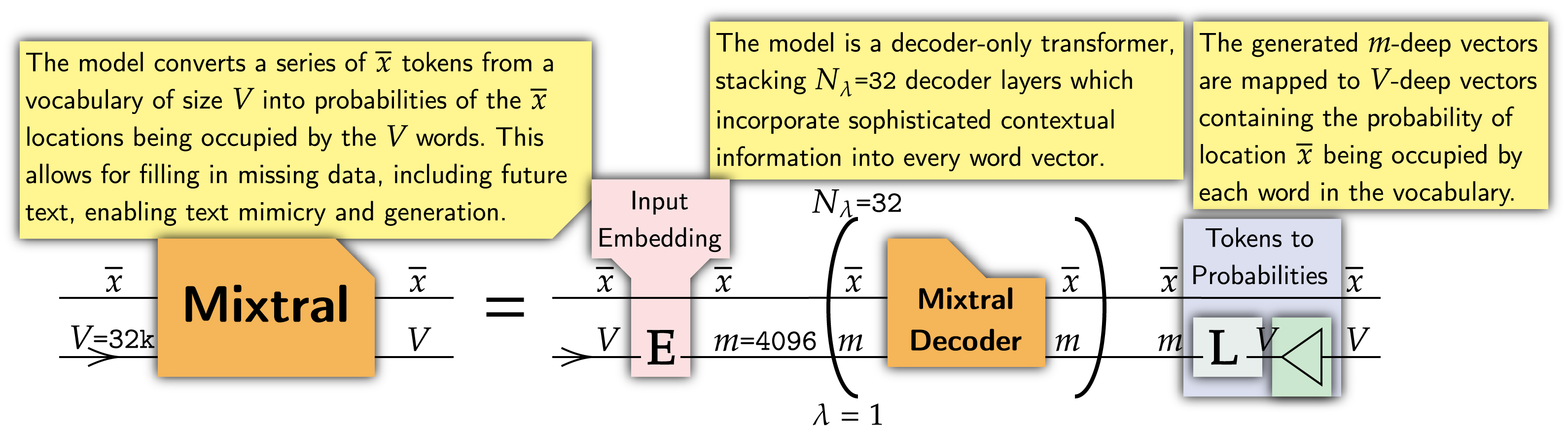
The overall structure of the architecture is shockingly simple. It is a decoder-only transformer. The model input is a series of tokens, which are embedded into vectors, and are then processed via decoder layers. The output is the probability of every location being occupied by some word, allowing for text infill and prediction.
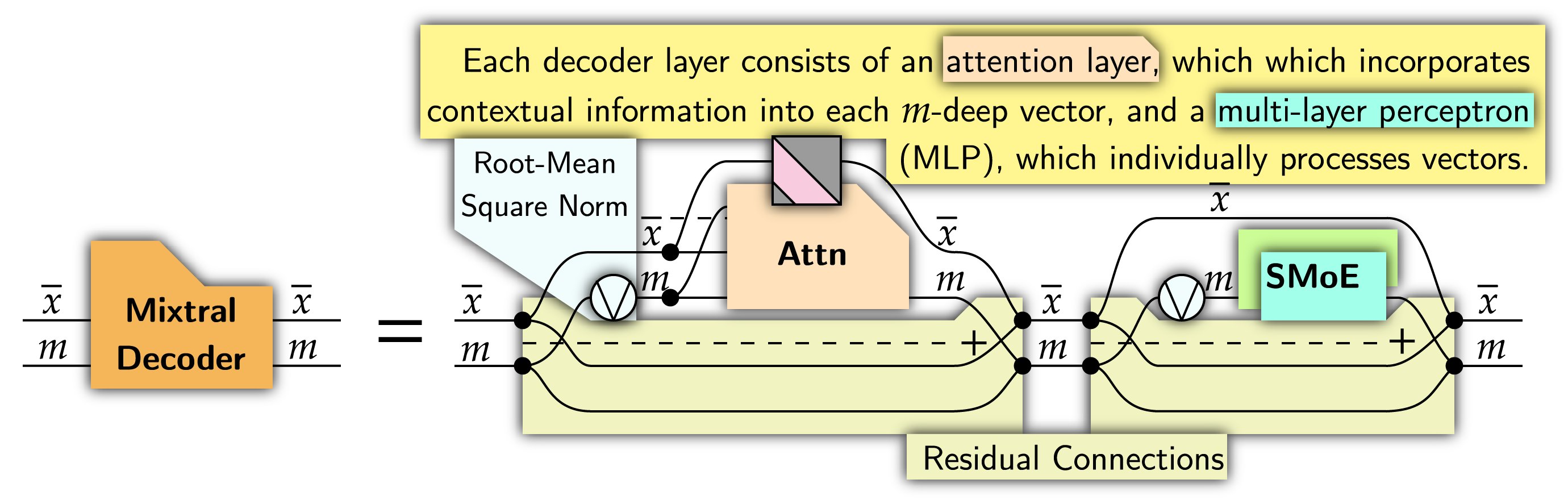
Every decoder layer has two key sections: an attention mechanism, which incorporates contextual information; and a multi-layer perceptron, which individually processes every word vector.
These are encapsulated in residual connections, which allows for training at depth. A combination of contextual and individual processing allows for sophisticated patterns to be discovered.
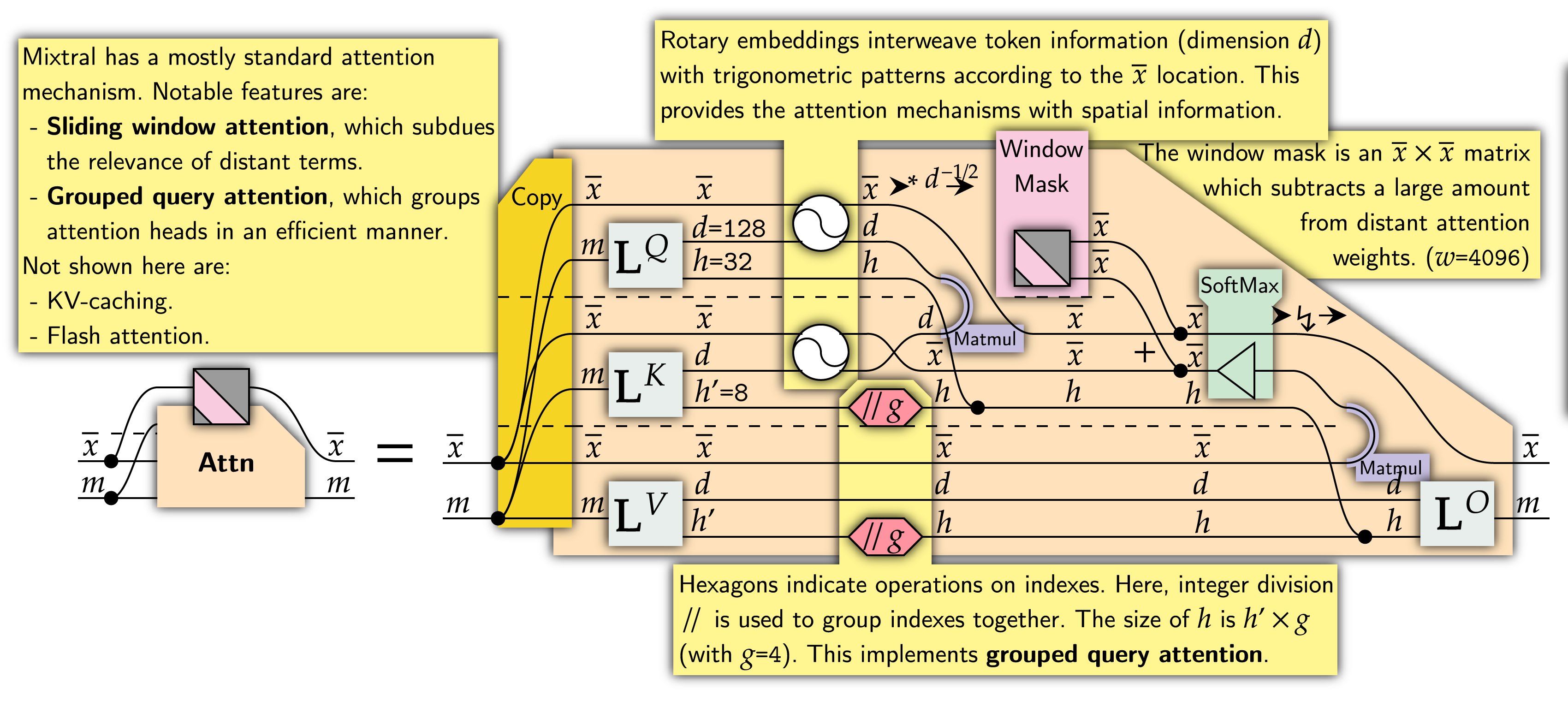
The attention mechanism used is similar to the original transformer's, which I cover in detail in my paper and briefly in a YT video. I list additional key features in the diagram, also covered in the original github and huggingface docs.
A key feature not explicitly shown in the below diagram is FlashAttention by @HazyResearch, which accelerates algorithms by decomposing attention to fit on kernels enabling high-speed memory access. I've been making progress using Neural Circuit Diagrams to derive such techniques. Explicitly stating variables in memory, linearity, and broadcasting is naturally displayed by neural circuit diagrams, lending themselves to formally understanding accelerated algorithms.
Finally, we get the key feature of Mixtral: Sparse Mixture of Experts (SMoE). MLP layers are immense consumers of computational resources. SMoEs have multiple layers ("experts") available. For every input, a weighted sum is taken over the outputs of the most relevant experts. SMoE layers can therefore learn sophisticated patterns while having relatively inexpensive compute cost.
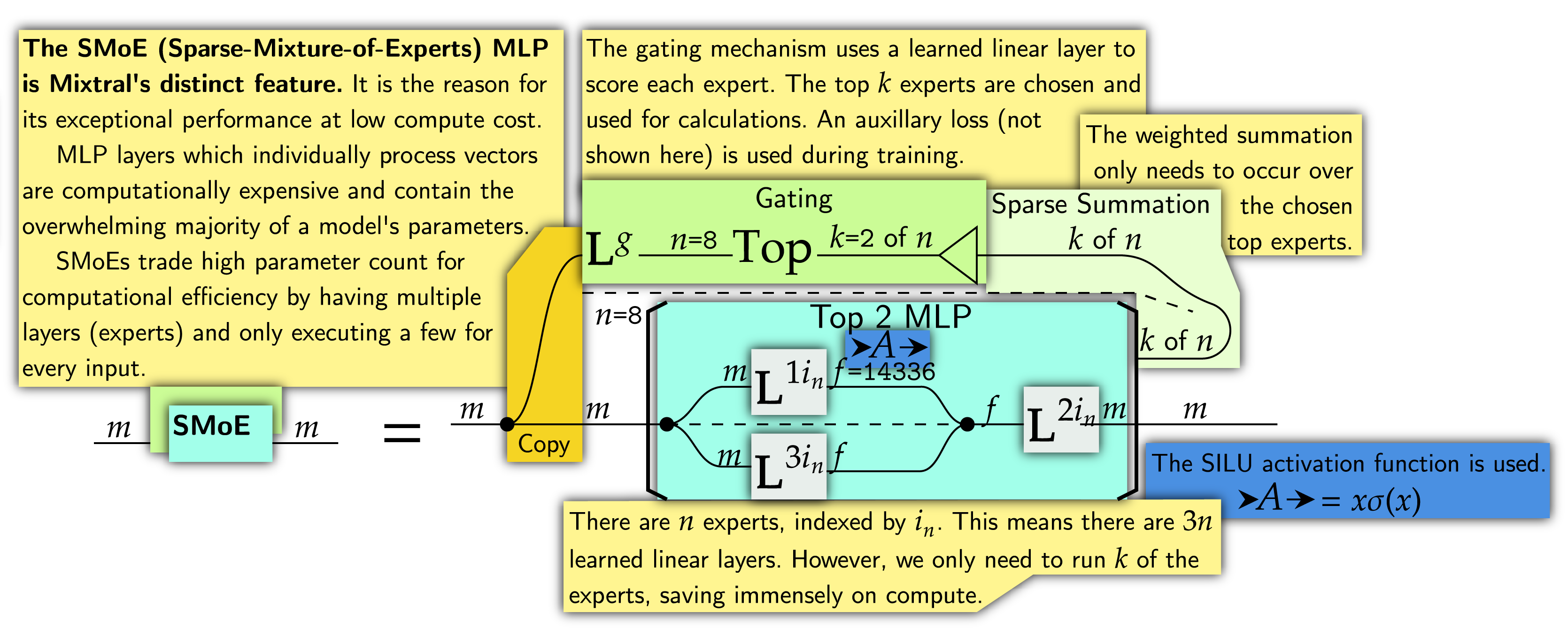
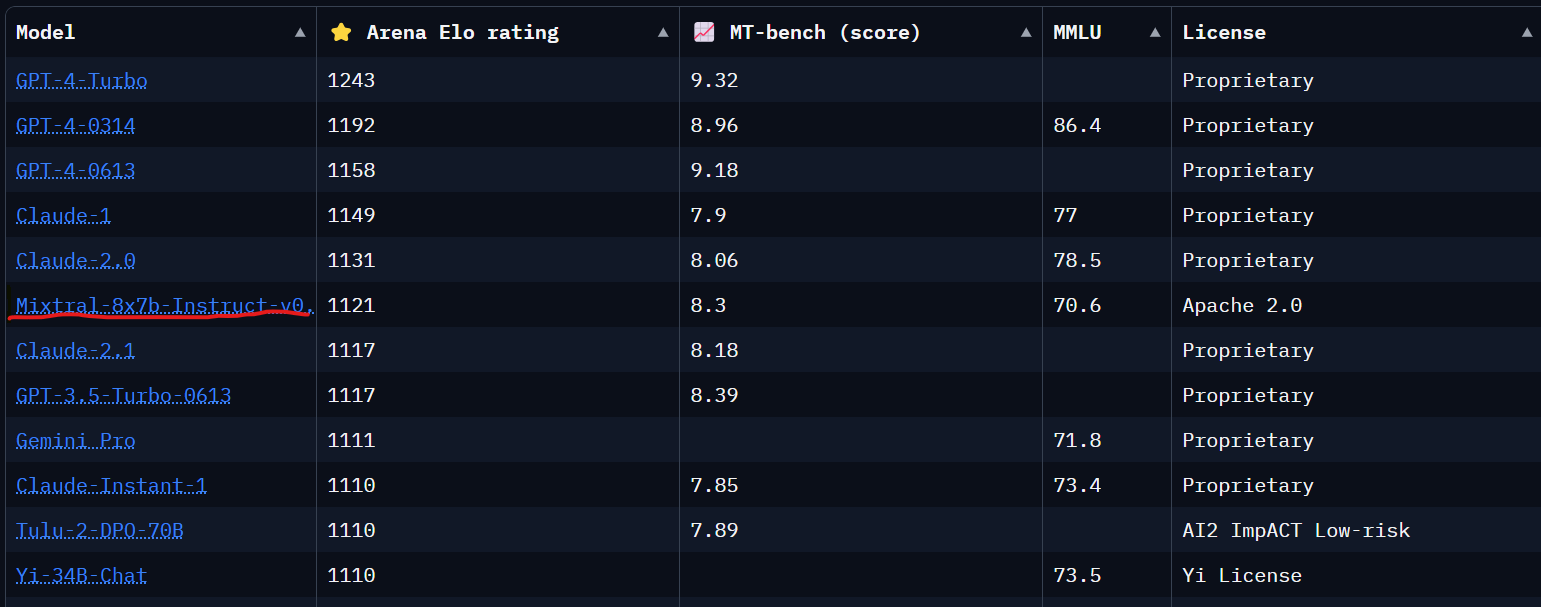
Conclusion. Mixtral is an immense achievement for the open-source AI community. The model is surprisingly simple. Compared to the original transformer architecture, encoders have been removed. Attention mechanisms have incurred 7 years' gradual innovations. The biggest change is the presence of SMoEs instead of plain MLPs. Mixtral has proven that open-source designs and SMoEs are on the frontier of ML development, and I suspect both will attract far more attention as a result.